


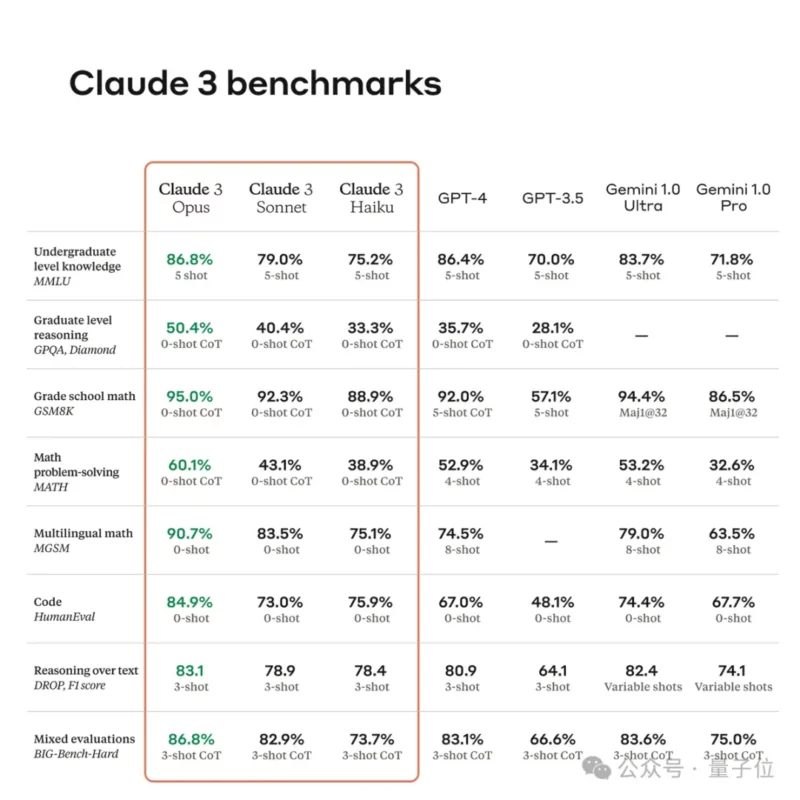
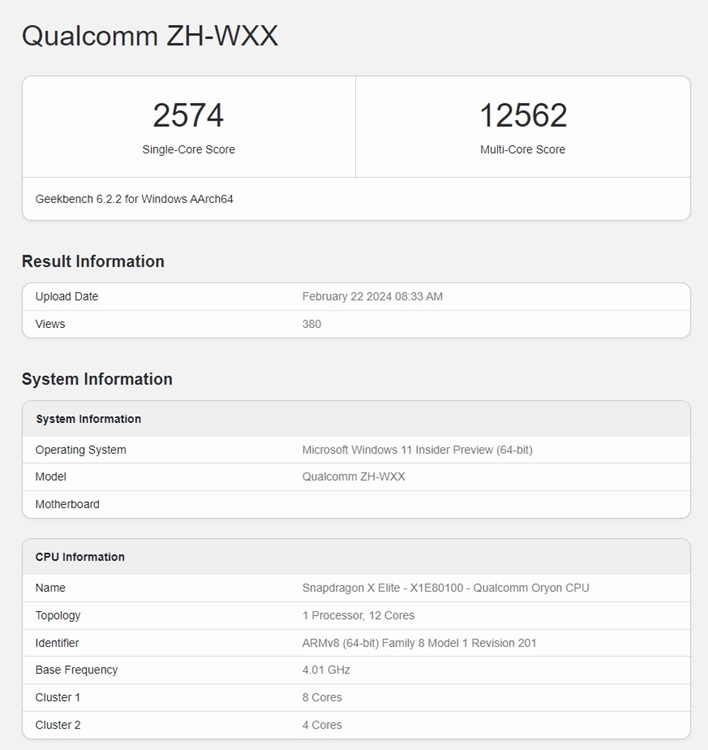
ChatGPT 于今天早上正式推出 Whisper API ,这是开源的托管版本Whisper 该公司于 9 月发布的语音转文本模型。与此同时,OpenAI 也对公司修改其 API 开发人员政策的条款后引起的质疑和批评做出回应。
回应称从今天开始,OpenAI 表示不会使用通过其 API 提交的任何数据用于“服务改进”,包括 AI 模型培训,也就是说默认不再使用客户提供的数据进行训练,除非客户或组织自己选择加入训练模型。此外,OpenAI 公司也正在实施 30 天数据保留政策,用户可以选择“根据用户需求”进行更严格的保留,并简化其条款和数据所有权,以明确用户拥有模型的输入和输出。
© 版权声明
本站所有文章,仅代表文章作者个人观点,如对观点有疑义时不用怀疑,您绝对是对的。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。
THE END














hi8个月前0
请问有详细一点的自己搭建的教程吗你好9个月前0
你好,可以再帮我看看吗? 我已经按照你的方法设定了,还是一样,wordpress后台的 Purge Varnish Cache 插件还是清除不到cache,依旧显示 the varnish control terminal is not responding at。谢谢 https://mjj.today/i/Srk2Tz https://mjj.today/i/Srkcoi你好9个月前0
对,你说的没错,我配置的时候改了一些东西,现在我按照你的教学,可以启动了,网页可以缓存了,不过wordpress 清除cache 那个插件没用的,我输入本地回环地址127.0.0.1 :6082 ,再输入API key ,插件显示the varnish control terminal is not responding at 127.0.0.1:6082,就你图片那样,然后试一下点击清除cache 那里,他显示error,研究了一天,还是没有不行。你好9个月前1
你好,为啥我按照你的方法,到第三部分,去到真正后源的服务器设定Varnish 部分,我填了真正后源的IP跟端口跟域名,然后重启 Varnish ,就出现这样了? 这是怎么回事? 谢谢 [Linux] AMH 7.1 https://amh.sh [varnish-6.6 start] ================================================== =========== [OK] varnish-6.6 is already installed. Could not delete 'vcl_boot.1713549650.959259/vgc.sym': No such file or directory Error: Message from VCC-compiler: VCL version declaration missing Update your VCL to Version 4 syntax, and add vcl 4.1; on the first line of the VCL files. ('/home/usrdata/varnish/default.conf' Line 1 Pos 1) ... #--- Running VCC-compiler failed, exited with 2 VCL compilation failedchu9个月前0
很完善的教程‘hu9个月前0
我用gmail EMAIL_SERVER="smtp://********@gmail.com:bpyfv*********[email protected]:587"叽喳9个月前0
MAIL_SERVER="smtp://[email protected]:[email protected]:587" 大佬 这个使用outlook 或者gmail 是什么样子的格式? 邮寄已经开启smtp了hu9个月前0
输入框的问题解决了,我没有设置反代,NEXTAUTH_URL改为域名+端口就好了