

六个月前,只有研究人员和博学者在关注大型语言模型的发展。但去年年底ChatGPT的推出震惊了世界:机器现在能够以一种与人类几乎没有区别的方式进行交流。它们能够在几秒钟内写出文本,甚至是跨越一系列令人眼花缭乱的主题领域的编程代码,而且往往是非常高的质量标准。正如GPT-4的推出所表明的那样,它们正在以流星般的速度进步,它们将像其他技术一样从根本上改变人类社会,因为它们有可能将一系列工作任务自动化–特别是在白领工人中,人们以前可能认为这是不可能的。
许多其他公司–特别是Google、苹果、Meta、百度和亚马逊等–也不甘落后,它们的人工智能很快就会涌入市场,附着在各种可能的应用和设备上。如果你是Bing的用户,语言模型已经出现在你的搜索引擎中,而且它们很快就会出现在其他地方。它们将出现在你的车里、你的手机里、你的电视上,当你试图给一家公司打电话时,它们会在电话的另一端等待。过不了多久,你就会在机器人中看到它们。
有一点值得安慰的是,OpenAI和其他这些大公司都意识到这些机器在垃圾邮件、错误信息、恶意软件、有针对性的骚扰和其他各种大多数人都认为会使世界变得更糟的使用情况方面的疯狂潜力。他们花了好几个月的时间在产品发布前手动削减这些能力。OpenAI首席执行官萨姆-奥特曼(Sam Altman)是许多担心政府行动不够迅速的人之一,没有以公共利益的名义为人工智能设置围栏。
但是,你可以花600美元自己建立一个语言模型呢?斯坦福大学的一个研究小组已经做到了这一点,斯坦福大学的Alpaca人工智能在许多任务上的表现与ChatGPT惊人的相似,其令人印象深刻的表现突出了整个行业及其令人敬畏的能力可能会迅速失去控制。
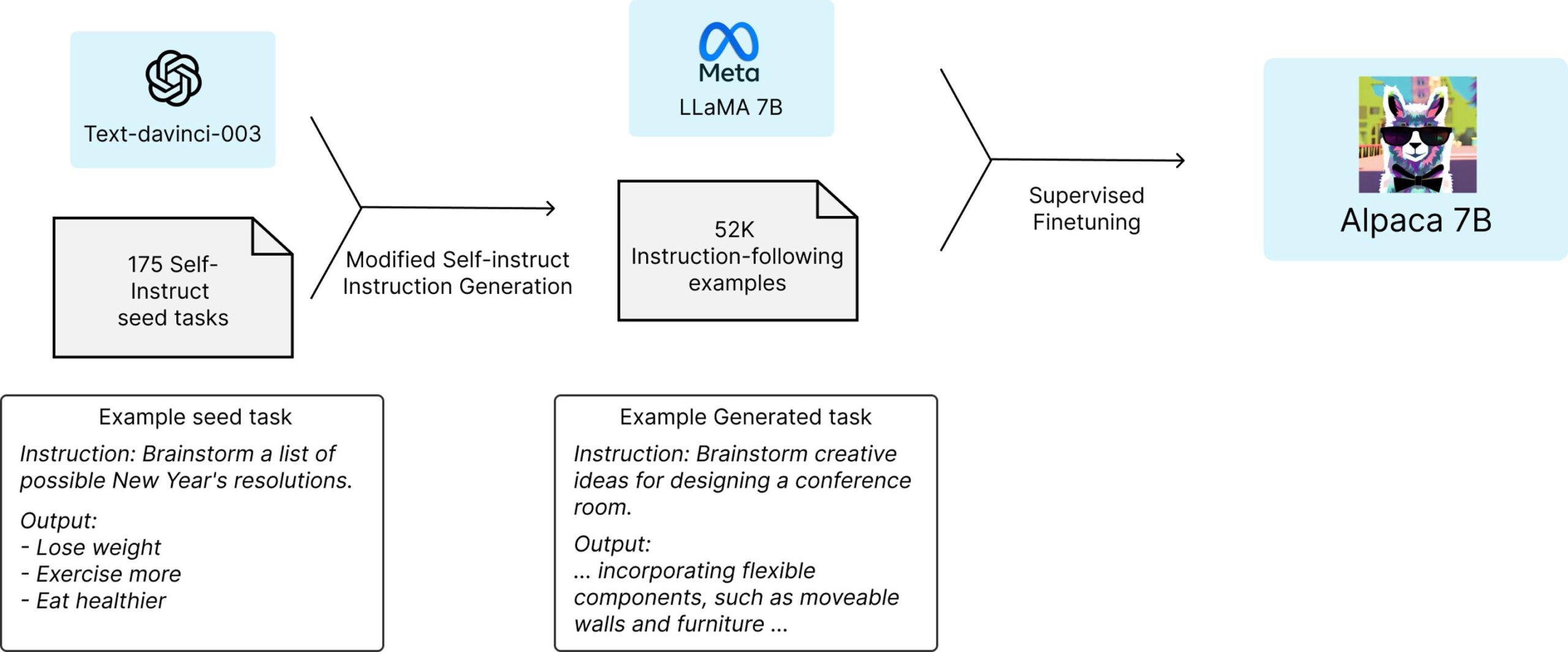
斯坦福大学的一个研究小组从Meta的开源LLaMA 7B语言模型开始–这是现有几个LLaMA模型中最小和最便宜的。在一万亿个”tokens”上进行预训练,这个小语言模型有一定的能力,但它在大多数任务中会明显落后于ChatGPT;GPT模型的主要成本,甚至主要竞争优势,主要来自OpenAI在后期训练中投入的大量时间和人力。读了十亿本书是一回事,但通过大量的问答式对话来教导这些AI的实际工作是另一回事。
因此,随着LLaMA 7B模型的建立和运行,斯坦福大学的团队基本上要求GPT采用175个由人类编写的指令/输出对,并开始以同样的风格和格式生成更多的指令/输出对,每次20个。这是通过OpenAI提供的一个有用的API自动完成的,在很短的时间内,该团队有大约52000个对话样本,用于后期训练LLaMA模型。生成这些大量训练数据的成本不到500美元。
然后,他们用这些数据来微调LLaMA模型–这个过程在8台80GB的A100云处理计算机上花了大约3个小时,这又花费了不到100美元。

斯坦福大学团队使用GPT-3.5给LLaMA 7B提供了一套关于如何完成其工作的指令
接下来,他们对产生的模型进行了测试,他们称之为Alpaca,与ChatGPT的底层语言模型在各种领域(包括电子邮件写作、社交媒体和生产力工具)进行对比。在这些测试中,Alpaca赢得了90项,GPT赢得了89项。
“鉴于模型规模小,指令跟随数据量不大,我们对这一结果相当惊讶,”该团队写道。”除了利用这个静态评估集,我们还对Alpaca模型进行了交互式测试,发现Alpaca在不同的输入集上往往表现得与text-davinci-003 [GPT-3.5]类似。我们承认,我们的评估在规模和多样性方面可能是有限的”。
该团队表示,如果他们寻求优化过程,他们可能会更便宜地完成这项工作。值得注意的是,任何希望复制人工智能的人现在都可以获得能力更强的GPT 4.0,以及几个更强大的LLaMA模型作为基础,当然也没有必要停留在52000个问题上。
斯坦福大学的团队已经在Github上发布了这项研究中使用的52000个问题,以及生成更多问题的代码,还有他们用来微调LLaMA模型的代码。该团队指出,”我们还没有对模型进行微调,使其安全无害”,并要求任何建立这种模型的人报告他们发现的安全和道德问题。
那么,有什么可以阻止任何人现在花100美元左右创建他们自己的人工智能,并以他们选择的方式训练它?OpenAI的服务条款确实带来了一些法律问题,它说:”你不能……使用服务的输出来开发与OpenAI竞争的模型”。而Meta说它在现阶段只允许学术研究人员在非商业许可下使用LLaMA,尽管这是一个有争议的问题,因为整个LLaMA模型在公布一周后就在4chan上泄露了。
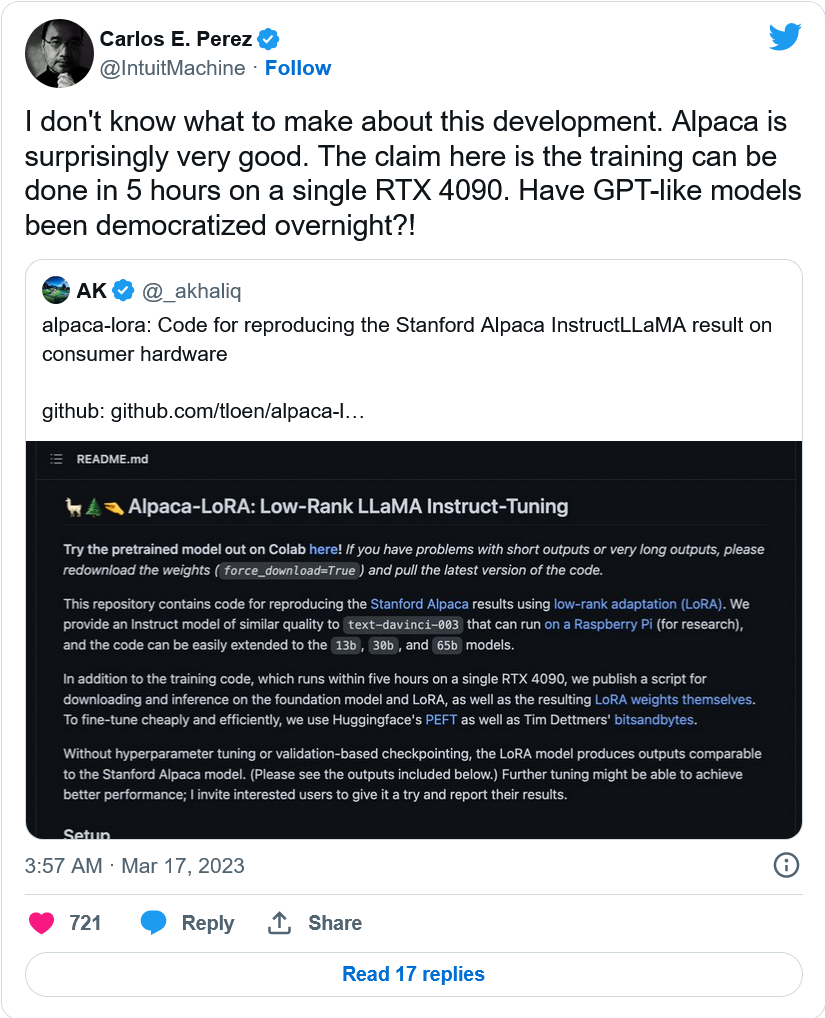
哦,还有一个小组说它已经设法消除了云计算成本,在Github上发布了更多的代码,可以在树莓派上运行,并在单个高端nVidia RTX 4090显卡上在5小时内完成训练过程。
这一切意味着什么?现在可以建立无限数量的不受控制的语言模型–由具有机器学习知识、不在乎条款和条件或软件盗版的人建立–只需花钱,而且并不是高不可攀。
这也给致力于开发自己的语言模型的商业人工智能公司泼了一盆冷水;如果所涉及的大部分时间和费用都发生在训练后阶段,而这项工作或多或少可以在回答50或100000个问题的时间内被窃取,那么公司继续砸钱是否有意义?
而对于我们其他人来说,嗯,很难说,但这个软件的强大功能肯定可以为专制政权、网络钓鱼行动、垃圾邮件发送者或任何其他可疑的人所用。
精灵已经从瓶子里出来了,而且似乎已经非常容易复制和重新训练了。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。














hi8个月前0
请问有详细一点的自己搭建的教程吗你好9个月前0
你好,可以再帮我看看吗? 我已经按照你的方法设定了,还是一样,wordpress后台的 Purge Varnish Cache 插件还是清除不到cache,依旧显示 the varnish control terminal is not responding at。谢谢 https://mjj.today/i/Srk2Tz https://mjj.today/i/Srkcoi你好9个月前0
对,你说的没错,我配置的时候改了一些东西,现在我按照你的教学,可以启动了,网页可以缓存了,不过wordpress 清除cache 那个插件没用的,我输入本地回环地址127.0.0.1 :6082 ,再输入API key ,插件显示the varnish control terminal is not responding at 127.0.0.1:6082,就你图片那样,然后试一下点击清除cache 那里,他显示error,研究了一天,还是没有不行。你好9个月前1
你好,为啥我按照你的方法,到第三部分,去到真正后源的服务器设定Varnish 部分,我填了真正后源的IP跟端口跟域名,然后重启 Varnish ,就出现这样了? 这是怎么回事? 谢谢 [Linux] AMH 7.1 https://amh.sh [varnish-6.6 start] ================================================== =========== [OK] varnish-6.6 is already installed. Could not delete 'vcl_boot.1713549650.959259/vgc.sym': No such file or directory Error: Message from VCC-compiler: VCL version declaration missing Update your VCL to Version 4 syntax, and add vcl 4.1; on the first line of the VCL files. ('/home/usrdata/varnish/default.conf' Line 1 Pos 1) ... #--- Running VCC-compiler failed, exited with 2 VCL compilation failedchu9个月前0
很完善的教程‘hu9个月前0
我用gmail EMAIL_SERVER="smtp://********@gmail.com:bpyfv*********[email protected]:587"叽喳9个月前0
MAIL_SERVER="smtp://[email protected]:[email protected]:587" 大佬 这个使用outlook 或者gmail 是什么样子的格式? 邮寄已经开启smtp了hu9个月前0
输入框的问题解决了,我没有设置反代,NEXTAUTH_URL改为域名+端口就好了