

人工智能研究机构OpenAI 3月14日发布了备受期待的文本生成AI模型GPT-4。GPT-4在关键方面对其前代GPT-3进行了改进,例如提供更符合事实的陈述,并允许开发人员更轻松地规定其风格和行为。它是多模态的模型,可以理解图像内容。但是,GPT-4也有严重的缺陷,与GPT-3一样,该模型会产生“幻觉”并犯下基本的推理错误。
GPT-4发布后,多家媒体关注的焦点是,OpenAI并没有透露很多细节,包括该模型有多大的参数,性能为什么更好。“GPT-4是该公司发布过的最机密的版本,标志着其从非营利性研究实验室全面转变为营利性科技公司。”《麻省理工科技评论》的文章称。
OpenAI的首席科学家伊利亚·苏茨克沃(Ilya Sutskever)在公告发布一个小时后通过视频通话与GPT-4团队成员交谈时说:“你知道,我们目前无法对此发表评论。”“竞争非常激烈。”
为了更好地了解GPT-4的开发周期及其功能和局限性,科技媒体TechCrunch 14日采访了OpenAI的联合创始人兼总裁格雷格·布罗克曼(Greg Brockman)。当被要求比较GPT-4和GPT-3时,布罗克曼说:“就是不同。”“(该模型) 仍然存在很多问题和错误……但你确实可以看到微积分或法律等技能的飞跃,从某些领域的非常糟糕到相对于人类来说实际上相当好。 ”

OpenAI高层,总左到右为首席技术官米拉·穆拉蒂、首席执行官山姆·奥特曼,总裁格雷格·布罗克曼,首席科学家伊利亚·苏茨克沃。图片来源:Jim Wilson
到底有多大的训练参数?
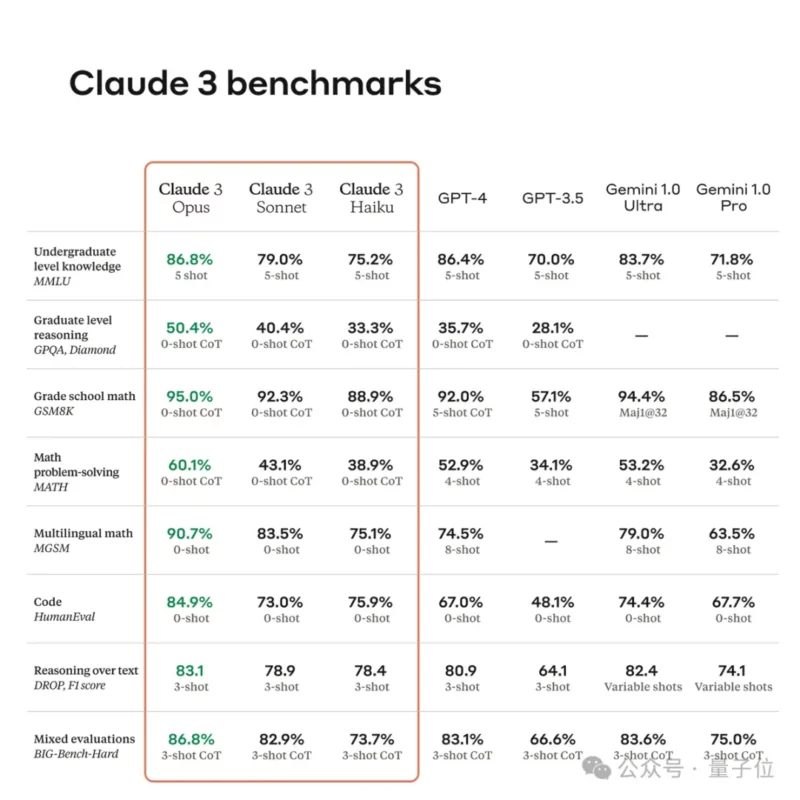
测试结果显示,在美国大学先修课程微积分BC考试中,GPT-4获得4分(满分5分),而GPT-3获得1分。GPT-3.5是GPT-3和GPT-4的中间模型,也获得4分。模拟律师考试方面,GPT-4以排名前10%的成绩通过,GPT-3.5的分数徘徊在后10%左右。(详见澎湃科技报道《OpenAI发布多模态大模型GPT-4:直接开放API,ChatGPT升级》)
GPT-4更有趣的方面之一是多模态。与GPT-3和GPT-3.5只能接受文本提示不同,GPT-4可以接受图像和文本提示来执行某些操作。这是因为GPT-4接受了图像和文本数据的训练,而其前代仅接受了文本训练。
GPT是Generative Pre-training Transformer(生成式预训练Transformer)的缩写。OpenAI于2018年推出具有1.17亿个参数的GPT-1模型,2019年推出具有15亿个参数的GPT-2,2020年推出有1750亿个参数的GPT-3。ChatGPT是OpenAI对GPT-3模型微调后开发出来的对话机器人。
但是,OpenAI这次选择不透露GPT-4训练数据的具体规模。在新闻公告里,OpenAI只表示,它使用与ChatGPT相同的方法取得了这些结果,通过人类反馈强化学习。这要求人类评分者对来自模型的不同响应进行评分,并使用这些分数来改进未来的输出。
OpenAI表示,训练数据来自“各种许可、创建和公开可用的数据源,其中可能包括公开可用的个人信息”,但当被询问具体细节时,布罗克曼拒绝了TechCrunch的询问。据悉,训练数据之前曾让OpenAI陷入关于版权的法律纠纷。
在接受《纽约时报》的采访时,布罗克曼则表示,OpenAI的数据集是“互联网规模的”,这意味着它涵盖了足够多的网站,可以提供互联网上所有说英语的人的代表性样本。

OpenAI的工作人员在办公。图片来源:Jim Wilson
“缓慢而有目的”地推广图像功能
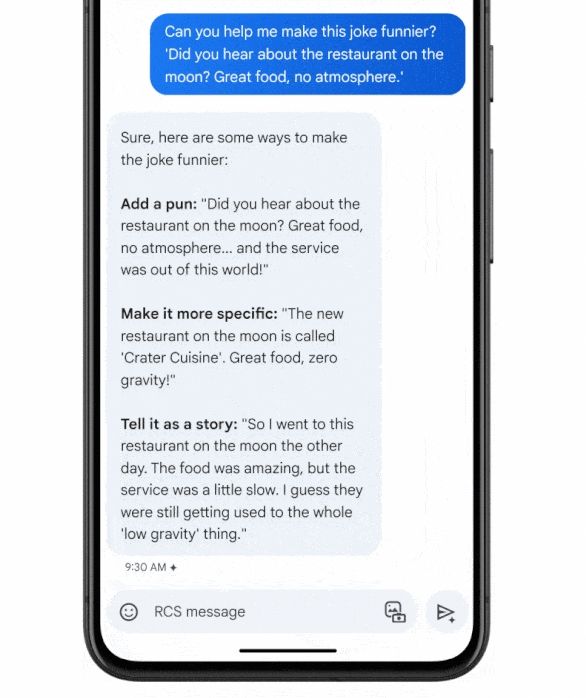
GPT-4的图像理解能力令人印象深刻。例如,输入提示“这张图片有什么好笑的?一个面板一个面板地描述它”,加上一张三面板图像,显示一条假VGA电缆被插入iPhone,GPT-4给出了每个面板的详细描述并正确解释了这个笑话:这个图像中的幽默来自于荒谬地将过时的大的VGA连接器插入小的现代智能手机充电口。

GPT-4解读图像内容。
“在过去几年里,一个好的多模态模型一直是许多大型技术实验室的圣杯。”开源大型语言模型BLOOM背后的人工智能初创公司Hugging Face的联合创始人托马斯·沃尔夫(Thomas Wolf)说, “但它仍然难以捉摸。”
从理论上讲,结合文本和图像可以让多模态模型更好地理解世界。“它可能能够解决语言模型的传统弱点,比如空间推理。”沃尔夫说。尚不清楚GPT-4是否如此。
目前只有一个OpenAI的合作伙伴可以使用GPT-4的图像分析功能——一款名为Be My Eyes的视障人士辅助应用程序(详见澎湃科技报道《第一批公司已采用GPT-4,都用它来做些什么?》。布罗克曼表示,随着OpenAI评估风险和收益,无论何时进行更广泛的推广,都将是“缓慢而有目的”的。
布罗克曼说,面部识别以及如何处理人物图像等方面存在政策问题。”“我们需要弄清楚危险区域在哪里,红线在哪里,然后随着时间的推移弄清楚这一点。”
此前,OpenAI围绕其文本到图像系统DALL-E 2面临了类似的道德困境。在最初禁用该功能后,OpenAI又允许用户上传人脸以使用人工智能图像生成系统对其进行编辑。当时,OpenAI称其安全系统的升级使面部编辑功能成为可能,因为最大限度地减少了深度造假,以及试图创造性、政治和暴力内容的潜在危害。
“从每3个月发布一个新模型转向不断改进”
另一个老问题是防止GPT-4以可能造成伤害的方式被使用,包括心理、金钱等方面。该模型发布数小时后,以色列网络安全初创公司Adversa AI发布了一篇博文,展示了绕过OpenAI内容过滤器并让GPT-4生成网络钓鱼电子邮件、对同性恋者的攻击性描述和其他令人反感的文本的方法。
这在语言模型领域并不是一个新现象。Meta的BlenderBot和ChatGPT也被提示说出非常冒犯的话,甚至透露有关其内部运作的敏感细节。但许多人曾希望,GPT-4可能会在这方面带来重大改进。
当被问及GPT-4的稳健性时,布罗克曼强调该模型已经接受了5个月的安全训练,并且在内部测试中,它响应OpenAI政策不允许的内容请求的可能性降低了82%。
“我们花了很多时间试图了解GPT-4的能力。”布罗克曼说,“把它带到外面的世界是我们学习的方式。我们不断进行更新,包括一堆改进,这样模型就更能扩展到你希望它处于的任何个性或某种模式。”
布罗克曼并不否认GPT-4的不足,但他强调了该模型新的缓解性控制工具,包括一种称为“系统”消息的API(应用程序编程接口)级能力。系统消息本质上是为GPT-4的互动设定基调并建立界限的指令。例如,一条系统信息可能是这样的:“你是一个总是以苏格拉底方式回答问题的辅导员。你从不给学生答案,而总是试图提出正确的问题,帮助他们学会自己思考。”系统信息作为护栏,可以防止GPT-4偏离方向。
“真正弄清楚GPT-4的语气、风格和内容一直是我们的一个重要焦点。”布鲁克曼说,“我认为我们开始有点了解如何做工程,如何有一个可重复的过程,让你得到可预测的结果,对人们真正有用。”
布罗克曼还提到了Evals,这是OpenAI刚刚开源的软件框架,用于评估其人工智能模型的性能,是OpenAI致力于“健全”其模型的一个标志。Evals让用户开发和运行评估GPT-4等模型的基准,同时检查其性能,这是一种模型测试的众包方法。
“通过Evals,我们可以以一种系统的形式看到用户关心的(用例),能够进行测试。”布罗克曼说,“我们(开源)的部分原因是,我们正在从每3个月发布一个新模型转向不断改进。做东西应该要衡量,对吗?当我们制作新的版本时,我们至少可以知道这些变化是什么。”
新的上下文窗口
布罗克曼还谈到了GPT-4的上下文窗口(context window),它指的是模型在生成其他文本之前可以考虑的文本。OpenAI正在测试GPT-4的一个版本,它可以“记住”大约50页的内容,是普通版GPT-4在其“记忆”中所能容纳的内容的五倍,是GPT-3的八倍。
布罗克曼认为,扩大的上下文窗口会带来新的、以前没有探索过的应用,特别是在企业中。他设想了一个为公司建造的人工智能聊天机器人,利用来自包括各部门员工的不同来源的背景和知识,以一种非常明智但对话性的方式回答问题。
这不是一个新概念。但布罗克曼提出的理由是,GPT-4的答案将比今天的聊天机器人和搜索引擎的答案有用得多。
“以前,该模型对你是谁、你对什么感兴趣等没有任何了解。”布洛克曼说,有了这种历史(更大的上下文窗口),肯定会让它更有能力……它会使人们能做的事更多。”
科学交流类似于产品新闻稿
即使看过了布罗克曼的采访,但GPT-4还有很多谜团没有解开。“OpenAI现在是一家完全封闭的公司,其科学交流类似于产品新闻稿。”沃尔夫说。
《麻省理工科技评论》认为,当下,GPT-4与其他多模态模型并驾齐驱,包括来自人工智能研究机构DeepMind的Flamingo。Hugging Face也正在开发一种开源多模态模型,其他人可以免费使用和改编该模型。面对这样的竞争,OpenAI将GPT-4更多地视为产品挑逗,而不是研究更新。
目前,构建和服务聊天机器人非常昂贵,因为它是在更大量的数据上训练的,所以GPT-4会增加OpenAI的成本。OpenAI的首席技术官米拉·穆拉蒂(Mira Murati)告诉《纽约时报》,如果该服务产生过多流量,该公司可能会限制对该服务的访问。
但从长远来看,OpenAI计划构建和部署可以处理多种媒体的系统,包括声音和视频。“我们可以采用所有这些通用知识技能,并将它们传播到各种不同领域。”布罗克曼说,“这将技术带入了一个全新的领域。”
许多其他公司正在排队等候。“对于大多数公司来说,启动这种规模的模型的成本是无法承受的,但是OpenAI所采用的方法使大型语言模型对于初创公司来说非常容易获得。”Tola Capital的联合创始人谢拉·古拉提(Sheila Gulati)说, “这将在GPT-4之上催化巨大的创新。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。














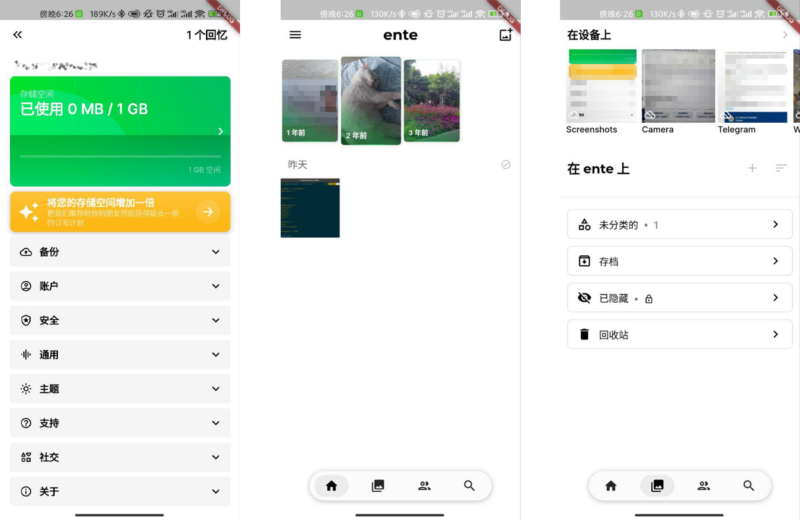
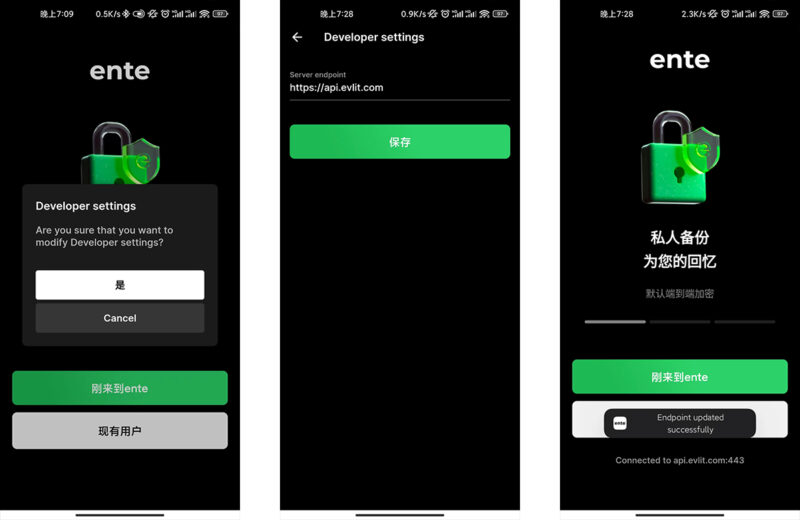
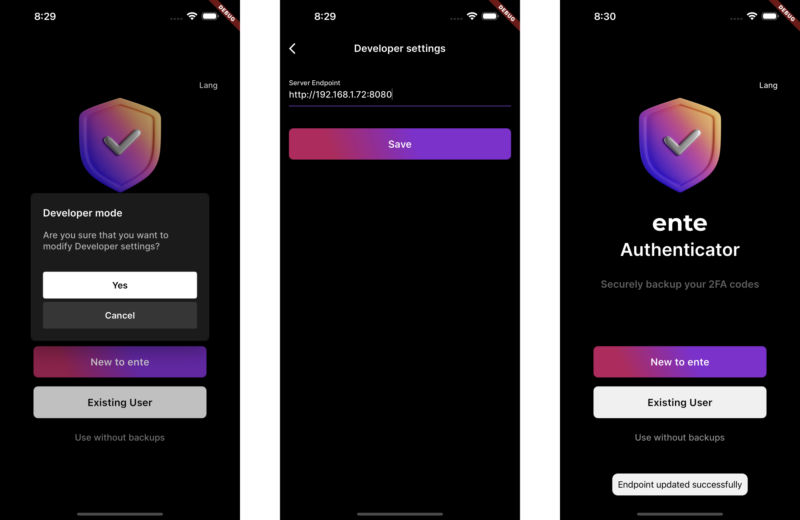
hi8个月前0
请问有详细一点的自己搭建的教程吗你好9个月前0
你好,可以再帮我看看吗? 我已经按照你的方法设定了,还是一样,wordpress后台的 Purge Varnish Cache 插件还是清除不到cache,依旧显示 the varnish control terminal is not responding at。谢谢 https://mjj.today/i/Srk2Tz https://mjj.today/i/Srkcoi你好9个月前0
对,你说的没错,我配置的时候改了一些东西,现在我按照你的教学,可以启动了,网页可以缓存了,不过wordpress 清除cache 那个插件没用的,我输入本地回环地址127.0.0.1 :6082 ,再输入API key ,插件显示the varnish control terminal is not responding at 127.0.0.1:6082,就你图片那样,然后试一下点击清除cache 那里,他显示error,研究了一天,还是没有不行。你好9个月前1
你好,为啥我按照你的方法,到第三部分,去到真正后源的服务器设定Varnish 部分,我填了真正后源的IP跟端口跟域名,然后重启 Varnish ,就出现这样了? 这是怎么回事? 谢谢 [Linux] AMH 7.1 https://amh.sh [varnish-6.6 start] ================================================== =========== [OK] varnish-6.6 is already installed. Could not delete 'vcl_boot.1713549650.959259/vgc.sym': No such file or directory Error: Message from VCC-compiler: VCL version declaration missing Update your VCL to Version 4 syntax, and add vcl 4.1; on the first line of the VCL files. ('/home/usrdata/varnish/default.conf' Line 1 Pos 1) ... #--- Running VCC-compiler failed, exited with 2 VCL compilation failedchu9个月前0
很完善的教程‘hu9个月前0
我用gmail EMAIL_SERVER="smtp://********@gmail.com:bpyfv*********[email protected]:587"叽喳9个月前0
MAIL_SERVER="smtp://[email protected]:[email protected]:587" 大佬 这个使用outlook 或者gmail 是什么样子的格式? 邮寄已经开启smtp了hu9个月前0
输入框的问题解决了,我没有设置反代,NEXTAUTH_URL改为域名+端口就好了