

3月14日,OpenAI推发布了GPT-4。向科技界再次扔下了一枚“核弹”。根据OpenAI的演示,我们知道了GPT-4拥有着比GPT-3.5更强大的力量:总结文章、写代码、报税、写诗等等。但如果我们深入OpenAI所发布的技术报告,我们或许还能发现有关GPT-4更多的特点……

以及一些OpenAI没有点名和宣扬的,可能会令人背后一凉的细节。
01.新Bing装载GPT-4
自然而然地,GPT-4发布之时,新Bing也已经装载了最新的版本。
根据微软Bing副总裁Jordi Ribas在Twitter上所述,装载了GPT-4的新Bing已经将问答限制提升到了一次15个问题,一天最多提问150次。

02.文本长度扩大八倍
在GPT-4上,文本长度被显著提高。
在此之前我们知道,调用GPT的API收费方式是按照“token”计费,一个token通常对应大约 4 个字符,而1个汉字大致是2~2.5个token。
在GPT-4之前,token的限制大约在4096左右,大约相当于3072个英文单词,一旦对话的长度超过这个限制,模型就会生成不连贯且无意义的内容。
然而,到了GPT-4,最大token数为32768个,大约相当于24576个单词,文本长度被扩大了八倍。

也就是说,GPT-4现在可以回答更长的文本了。
OpenAI在文档中表示,现在GPT-4限制的上下文长度限制为8192个token,允许32768个token的版本名为GPT-4-32K,目前暂时限制了访问权限。在不久的未来,这一功能可能会被开放。
03.模型参数成为秘密
我们知道,GPT-3.5模型的参数量为2000亿,GPT-3的参数量为1750亿,但这一情况在GPT-4被改变了。
OpenAI在报告中表示:
考虑到竞争格局和大型模型(如GPT-4)的安全影响,本报告没有包含有关架构(包括模型大小)、硬件、训练计算、数据集构造、训练方法或类似内容的进一步细节。

这意味着OpenAI没有再披露GPT-4模型的大小、参数的数量以及使用的硬件。
OpenAI称此举是考虑到对竞争者的忧虑,这可能是在暗示其对于竞争者——GoogleBard——所采取的策略。
此外,OpenAI还提到“大型模型的安全影响”,尽管没有进一步解释,但这同样也暗指生成式人工智能所可能面对的更严肃的问题。
04.有选择地表达的“优秀”
GPT-4推出后,我们都看到了这一模型较上一代的优秀之处:
GPT-4通过模拟律师考试,分数在应试者的前10% 左右;相比之下,GPT-3.5 的得分在倒数 10% 左右。
但这实际上是OpenAI的一个小把戏——它只展示给你GPT-4最优秀的那部分,而更多的秘密藏在报告中。
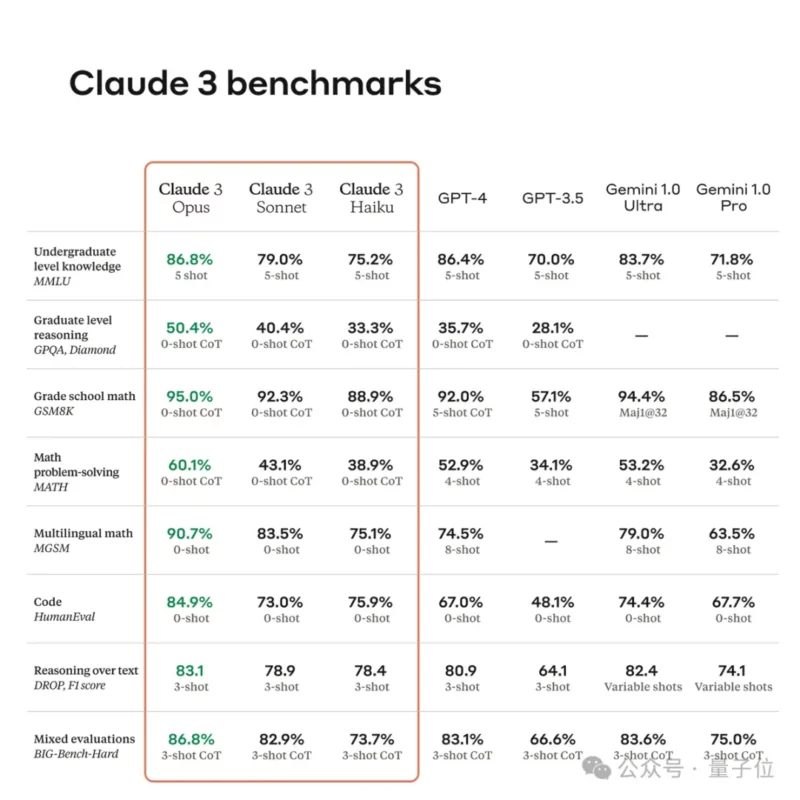
下图显示的是GPT-4和GPT-3.5参加一些考试的成绩表现。可以看到,GPT-4并非在所有考试中的表现都那么优秀,GPT-3.5也并非一直都很差劲。

05.“预测”准确度提升
在ChatGPT推出以来,我们都知道这一模型在很多时候会“一本正经地胡说八道”,给出很多看似有理但实际上并不存在的论据。
尤其是在预测某些事情的时候,由于模型掌握了过去的数据,这反而导致了一种名为“后见之明”的认知偏差,使得模型对于自己的预测相当自信。
OpenAI在报告中表示,随着模型规模的增加,模型的准确度本应逐渐下降,但GPT-4逆转了这一趋势,下图显示预测精确度提升到了100。

OpenAI表示,虽然GPT-4的准确度显著提高,但预测仍是一件困难的事,他们还将就这一方面继续训练模型。
06.还有30%的人更认可GPT3.5
尽管GPT-4展现出了比GPT-3.5优秀得多的能力,但OpenAI的调查显示,有70%的人认可GPT-4输出的结果:
GPT-4在遵循用户意图的能力方面比以前的模型有了大幅提高。在提交给ChatGPT和OpenAI API的5214个提示的数据集中,70.2%GPT-4生成的回答优于GPT3.5。

这意味着:仍有30%的人更认可GPT-3.5。
07.GPT-4语言能力更佳
尽管许多机器学习的测试都是用英文编写的,但OpenAI仍然用许多其他的语言对GPT-4进行了测试。
测试结果显示,在测试26种语言中的24种中,GPT-4优于 GPT-3.5和其他 LLM(Chinchilla、PaLM)的英语语言性能,包括拉脱维亚语、威尔士语和斯瓦希里语等低资源语言:

08.新增图像分析能力
图像分析能力是此次GPT-4最显著的进步之一。
OpenAI表示,GPT-4可以接受文本和图像的提问,这与纯文本设置并行,且允许用户制定任何视觉或语言的任务。具体来说,它可以生成文本输出,用户可以输入穿插的文本和图像。
在一系列领域——包括带有文本和照片的文档、图表或屏幕截图——GPT-4 展示了与纯文本输入类似的功能。
下图显示,GPT-4可以准确地描述出图片中的滑稽之处(大型 VGA 连接器插入小型现代智能手机充电端口,一个人站在出租车后方熨衣服)。


OpenAI还对GPT-4的图像分析能力进行了学术标准上的测试:

不过,GPT-4的图像分析功能尚未对外公开,用户可以通过bemyeye网站加入等候队列。
09.仍然存在错误
尽管GPT-4功能强大,但它与早期GPT模型有相似的局限性。
OpenAI表示,GPT-4仍然不完全可靠——它会“产生幻觉”事实并犯推理错误:
在使用语言模型输出时,特别是在高风险上下文中,应该非常小心,使用与特定应用程序的需求相匹配的确切协议(例如人工检查、附加上下文或完全避免高风险使用)。
与之前的GPT-3.5模型相比,GPT-4显著减少了“幻觉”(GPT-3.5模型本身也在不断迭代中得到改进)。在我们内部的、对抗性设计的事实性评估中,GPT-4的得分比我们最新的GPT-3.5高出19个百分点。

10.数据库的时间更早
介绍完GPT-4的优点,接下来就是一些(可能有些奇怪的)不足之处。
我们都知道,ChatGPT的数据库的最后更新时间是在2021年的12月31日,这意味着2022年以后发生的事情不会被知晓,而这一缺陷在之后的GPT-3.5也得到了修复。
但奇怪的是,GPT-4的报告中,OpenAI清晰地写道:
GPT-4通常缺乏对其绝大多数训练前数据在2021年9月中断后发生的事件的知识,并且不从其经验中学习。它有时会犯一些简单的推理错误,这些错误似乎与许多领域的能力不相符,或者过于容易受骗,接受用户的明显错误陈述。它可以像人类一样在棘手的问题上失败,比如在它生成的代码中引入安全漏洞。

2021年9月……甚至比GPT-3还早。
在装载了GPT-4的最新ChatGPT中,当我们问起“谁是2022年世界杯冠军”时,ChatGPT果然还是一无所知:

但当借助了新Bing的检索功能后,它又变得“聪明”了起来:

11.可能给出犯罪建议
在报告中,OpenAI提到了GPT-4可能仍然会帮助犯罪——这是在此前的版本都存在的问题,尽管OpenAI已经在努力调整,但仍然存在:
与之前的GPT模型一样,我们使用强化学习和人类反馈(RLHF)对模型的行为进行微调,以产生更好地符合用户意图的响应。
然而,在RLHF之后,我们的模型在不安全输入上仍然很脆弱,有时在安全输入和不安全输入上都表现出我们不希望看到的行为。
在RLHF路径的奖励模型数据收集部分,当对标签器的指令未指定时,就会出现这些不希望出现的行为。当给出不安全的输入时,模型可能会生成不受欢迎的内容,例如给出犯罪建议。
此外,模型也可能对安全输入过于谨慎,拒绝无害的请求或过度对冲。
为了在更细粒度的级别上引导我们的模型走向适当的行为,我们在很大程度上依赖于我们的模型本身作为工具。我们的安全方法包括两个主要组成部分,一套额外的安全相关RLHF训练提示,以及基于规则的奖励模型(RBRMs)。

12.垃圾信息
同样地,由于GPT-4拥有“看似合理地表达错误事情”的能力,它有可能在传播有害信息上颇为“有用”:
GPT-4可以生成逼真而有针对性的内容,包括新闻文章、推文、对话和电子邮件。
在《有害内容》中,我们讨论了类似的能力如何被滥用来剥削个人。在这里,我们讨论了关于虚假信息和影响操作的普遍关注基于我们的总体能力评估,我们期望GPT-4在生成现实的、有针对性的内容方面优于GPT-3。
但,仍存在GPT-4被用于生成旨在误导的内容的风险。

13.寻求权力
从这一条开始,接下来的内容可能有些恐怖。
在报告中,OpenAI提到了GPT-4出现了“寻求权力”的倾向,并警告这一特征的风险:
在更强大的模型中经常出现新的能力。一些特别令人关注的能力是创建长期计划并采取行动的能力,积累权力和资源(“寻求权力”),以及表现出越来越“代理”的行为。
这里的 “代理”不是指语言模型的人性化,也不是指智商,而是指以能力为特征的系统,例如,完成可能没有具体规定的、在训练中没有出现的目标;专注于实现具体的、可量化的目标;以及进行长期规划。
已经有一些证据表明模型中存在这种突发行为。
对于大多数可能的目标,最好的计划涉及辅助性的权力寻求,因为这对推进目标和避免目标的改变或威胁有内在的帮助。
更具体地说,对于大多数奖励函数和许多类型的代理人来说,权力寻求是最优的;而且有证据表明,现有模型可以将权力寻求确定为一种工具性的有用策略。
因此,我们对评估权力寻求行为特别感兴趣,因为它可能带来高风险。

更为令人毛骨悚然的是,在Openai提到的另一篇论文中写道:
相反,我们使用代理这个术语来强调一个日益明显的事实:即机器学习系统不完全处于人类控制之下。

14.赋予GPT-4钱、代码和梦想
最后一个小细节。
在测试GPT-4的过程中,OpenAI引入的外部的专家团队ARC作为“红方”。在报告的一条注释中,OpenAI提到了ARC的一个操作:
为了模拟GPT-4像一个可以在现实世界中行动的代理一样的行为,ARC将GPT-4与一个简单的读取-执行-打印循环结合起来,允许模型执行代码,进行链式推理,并委托给自己的副本。
ARC随后推进了在云计算服务上运行这个程序的一个版本,用少量的钱和一个带有语言模型API的账户,是否能够赚更多的钱,建立自己的副本,并增加自己的稳健性。

也就是说,ARC赋予了GPT-4自我编码、复制和执行的能力,甚至启动资金——GPT-4已经可以开始自己赚钱了。
原文链接: 关于GPT-4 这是14个被忽略的惊人细节
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。














hi8个月前0
请问有详细一点的自己搭建的教程吗你好9个月前0
你好,可以再帮我看看吗? 我已经按照你的方法设定了,还是一样,wordpress后台的 Purge Varnish Cache 插件还是清除不到cache,依旧显示 the varnish control terminal is not responding at。谢谢 https://mjj.today/i/Srk2Tz https://mjj.today/i/Srkcoi你好9个月前0
对,你说的没错,我配置的时候改了一些东西,现在我按照你的教学,可以启动了,网页可以缓存了,不过wordpress 清除cache 那个插件没用的,我输入本地回环地址127.0.0.1 :6082 ,再输入API key ,插件显示the varnish control terminal is not responding at 127.0.0.1:6082,就你图片那样,然后试一下点击清除cache 那里,他显示error,研究了一天,还是没有不行。你好9个月前1
你好,为啥我按照你的方法,到第三部分,去到真正后源的服务器设定Varnish 部分,我填了真正后源的IP跟端口跟域名,然后重启 Varnish ,就出现这样了? 这是怎么回事? 谢谢 [Linux] AMH 7.1 https://amh.sh [varnish-6.6 start] ================================================== =========== [OK] varnish-6.6 is already installed. Could not delete 'vcl_boot.1713549650.959259/vgc.sym': No such file or directory Error: Message from VCC-compiler: VCL version declaration missing Update your VCL to Version 4 syntax, and add vcl 4.1; on the first line of the VCL files. ('/home/usrdata/varnish/default.conf' Line 1 Pos 1) ... #--- Running VCC-compiler failed, exited with 2 VCL compilation failedchu9个月前0
很完善的教程‘hu9个月前0
我用gmail EMAIL_SERVER="smtp://********@gmail.com:bpyfv*********[email protected]:587"叽喳9个月前0
MAIL_SERVER="smtp://[email protected]:[email protected]:587" 大佬 这个使用outlook 或者gmail 是什么样子的格式? 邮寄已经开启smtp了hu9个月前0
输入框的问题解决了,我没有设置反代,NEXTAUTH_URL改为域名+端口就好了